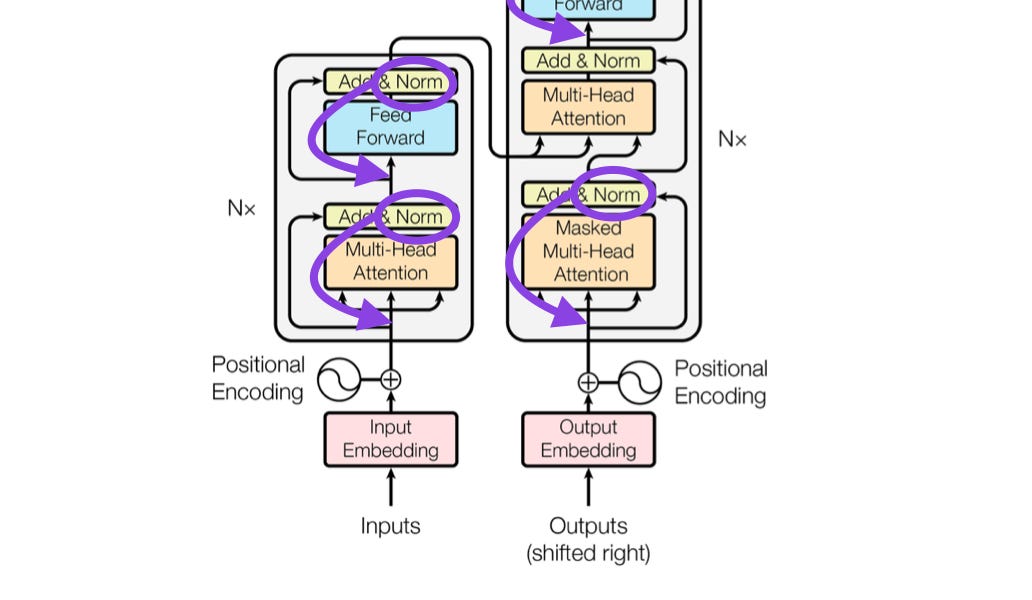
Summary: About LayerNorm Variants in the Original Transformer Paper, and Some Other Interesting Historical Tidbits About LLMs
For instance, in 1991, which is about two-and-a-half decades before the original transformer paper above (“Attention Is All You Need”), Juergen Schmidhuber proposed an alternative to recurrent neural networks called Fast Weight Programmers (FWP).
Source: Annotated figure based on https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2
(3) Universal Language Model Fine-tuning for Text Classification (2018) by Howard and Ruder, https://arxiv.org/abs/1801.06146
This is another paper that’s very interesting from a historical perspective.
This recipe — training a language model on a large corpus and then finetuning it on a downstream task — is the central approach used in transformer-based models and foundation models like BERT, GPT-2/3/4, RoBERTa, and others.
However, it’s still noteworthy since it effectively proposed pretraining language models and transfer learning for downstream tasks.
While it was written one year after the original Attention Is All You Need transformer was released, it doesn’t involve transformers but instead focuses on recurrent neural networks.
Similar Articles
About LayerNorm Variants in the Original Transformer Paper, and Some Other Interesting Historical Tidbits About LLMs
A few months ago, I shared the article, Understanding Large Language Models: A Cross-Section of the Most Relevant Literature To Get Up to Speed, and the positive feedback was very motivating! So, I also added a few papers here and there to keep the list fresh and relevant.
Read the complete article at: magazine.sebastianraschka.com